Create Enricher
Step-by-step instructions to create enrichers for all supported enricher types.
Create Enricher
Start from the enrichers list page, then click Create.
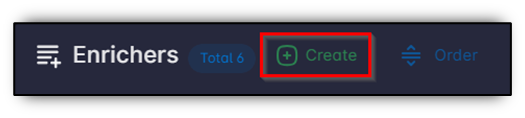
Use the shared steps below for all enricher types:
- Open the enrichers list, then click Create.
- Fill the generic Enricher Information fields.
- Select Enricher Type.
- Fill type-specific Enricher Parameters.
- Click Create.
Enricher Information
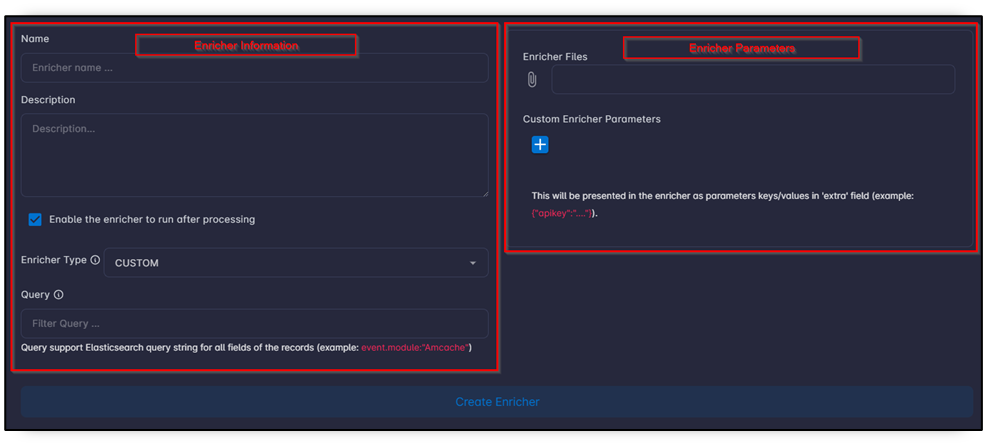
| Field | Description |
|---|---|
| Enricher name | Unique enricher name. |
| Enricher Description | Readable purpose and scope. |
| Enable the enricher to run after processing | Enable/disable automatic enricher execution after processing (auto_run). |
| Enricher Type | Select one of MAPPER, LOOKUP, CUSTOM, FEEDS. |
| Filter Query | Lucene query filter to run only on matching records. |
Filter query examples:
exists:Data.Event.EventData.NewProcessName OR exists:Data.Pathexists:file.hash.sha1 OR exists:process.hash.sha1
Note
The Filter Query uses paths starting from first level (Data, event, etc.), not _source.
Mapper Enricher
Mapper enricher copies data from one field to another in the same record.
Configuration
src_field: source field path.dst_field: destination field path.replace_org: remove original field after copy.

Package requirements
- No package upload is required for
MAPPER.
Example behavior:
- Map
_source.Data.Event.EventData.NewProcessNameand_source.Data.Pathinto_source.Data.Executableswhile keeping original fields whenreplace_orgis disabled.
Feed Enricher
Feeds enricher checks selected fields from incoming records against collected feed data.
If matched, it writes feed metadata (for example feed name, tags, last-updated values) to a target field, commonly _source.alerts for alert-oriented use cases.
Configuration
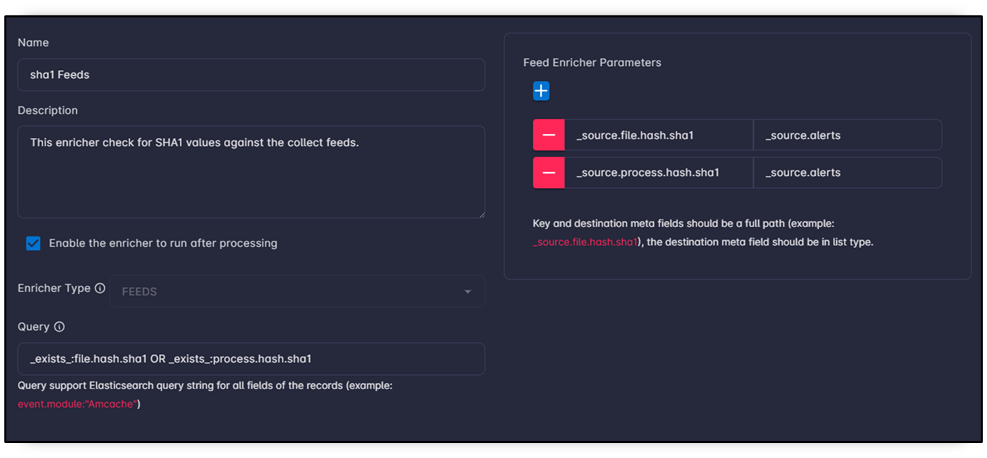
key: field path used to match feed records.meta: destination metadata field path.- You can configure multiple fields for matching in one FEEDS enricher.
Typical behavior:
- Apply query gate (if configured).
- Extract values from configured feed keys in the record.
- Match values against feed store.
- Write matched feed metadata into destination field.
Feeds scenario example:
- Query gate:
exists:file.hash.sha1 OR exists:process.hash.sha1. - Enricher reads
_source.file.hash.sha1and_source.process.hash.sha1. - Enricher checks values against collected feeds.
- On match, feed metadata (name, tags, updated time, and related context) is stored in destination metadata field.
Package requirements
- No package upload is required for
FEEDS.
Note
Validation from feeds management is case insensitive. If your record has field value Evil.exe and the feeds has IoCs of evil.exe, it will trigger the alert.
Custom Enricher
Custom enricher executes Python logic after parsing to perform advanced record manipulation.
Note
If the processing is specific to the parser, it is recommended to do the processing in the parser itself. Custom enricher is useful if you want to run a script that processes records from multiple parsers.
Configuration
- Add optional Extra Parameters key/value pairs.
- Access these values in
parameters['extra']inside the script.
Package requirements
Expected package content:
__init__.py(empty file, required)enricher.pywith functionenricher(enricher, records, utils=None)
Note
Ensure both files are in the first level of the zip:
/enricher.py/__init__.py
The function receives:
| Parameter | Description |
|---|---|
enricher | Enricher definition as JSON-like object. |
records | List of JSON records to enrich. |
utils | Helper utilities for JSON access, logging, search/database functions, and more. |
enricher.py example (CUSTOM)
Note
The enricher function should raise Exception for any issues if the enricher fails for any reason.
import json
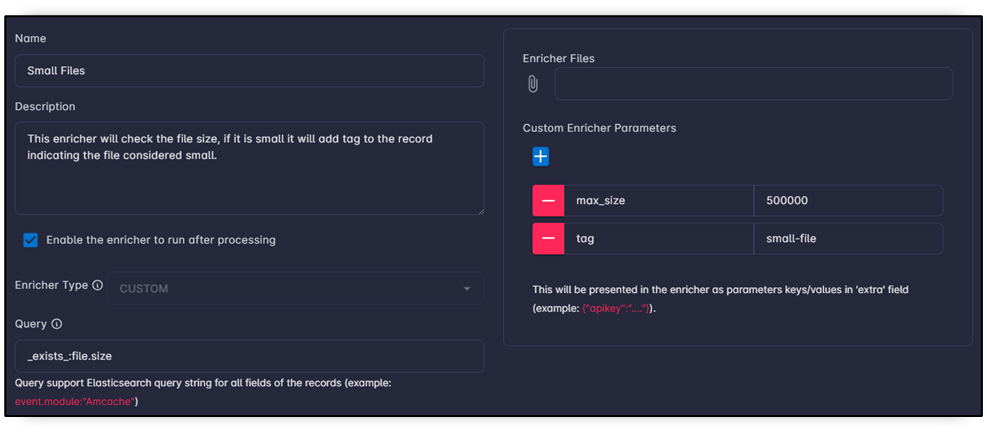
# this enricher add tag "small_file_size"
def enricher(enricher , records , utils=None):
parameters = json.loads(enricher['parameters']) # get the parameters of the enricher
# this is the max size if the file size less it will consider it small file
max_size = parameters['extra']['max_size'] if 'max_size' in parameters['extra'].keys() else 1000000
max_size = int(max_size)
tag = parameters['extra']['tag'] if 'tag' in parameters['extra'].keys() else 'small_file_size'
# iterate over all records
for r in range(0 , len(records)):
# get the file size from the record on field "_source.file.size"
size = utils.json.get(j=records[r] , p='_source.file.size')
# if the record has a field '_source.file.size' and the file size less than max_size then add tag to the record
if size[0] and int(size[1]) < max_size:
if 'tags' not in records[r]['_source'].keys():
# if there is no tags field before, add tag as a list
records[r]['_source']['tags'] = [tag]
else:
# if the tag field already exists, then add the tag to it.
records[r]['_source']['tags'].append(tag)
return recordsNote
Inside the enricher function, the record object paths start from _source (for example, to access the tags field use _source.tags).
Warning
Any record not returned in the records list will be dropped by default.
This script:
- Reads
_source.file.sizefor each record. - Compares against
parameters['extra']['max_size']. - Adds/appends a tag from
parameters['extra']['tag']. - Returns enriched
records.
To upload the enricher script, first you need to compress the enricher folder into zip file, make sure that the enricher.py and __init__.py are stored directly in the first level of the zip file (/enricher.py and /__init__.py).
Lookup Enricher
Lookup enricher is similar to custom enricher, but is designed for external-source enrichment with cache-aware behavior.
Some differences between custom and lookup enricher :
- lookup enrichers execute after all enrichers finished and data stored in the database.
- lookup enricher purpose is to lookup data from external sources (such as TIP, VirusTotal, etc.).
Configuration
- Lookup execution happens after parser and non-lookup enricher results are stored.
- It is intended for external lookups (TIP platforms, VirusTotal, and similar systems).
- It can use
enricher_<enricher_id>cache records to avoid repeated external calls. src_fieldvalue is stored askeyin lookup cache records.dest_fieldguides where enriched output is written in source record.- Expiration: cache validity period.
- Fields:
src_fieldanddest_field, where source values are stored as cache keys.
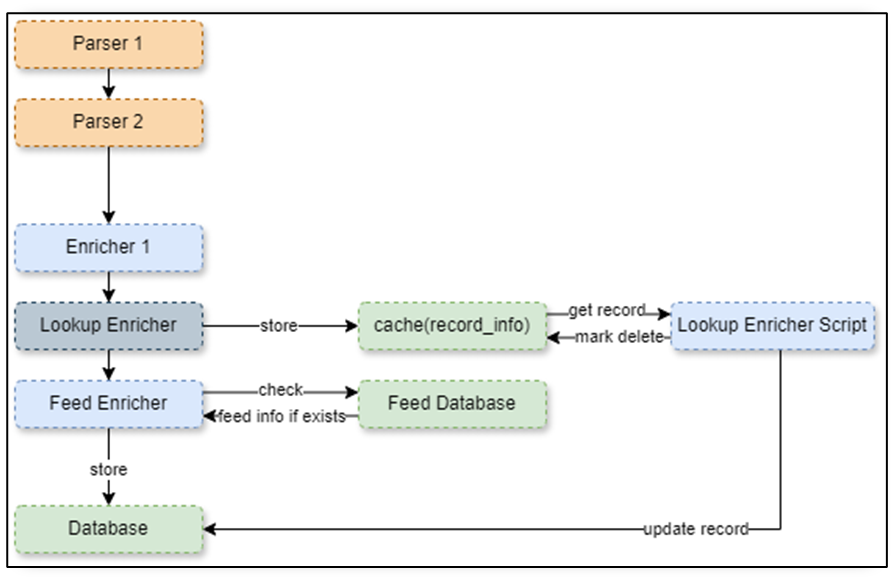
The following diagram illustrates the execution flow of the parsers and enrichers. Lookup enricher will copy record information such as the database index ID, record ID, and store it in database index named enricher_<enricher_id>, after the execution of all parsers and enrichers, the enricher script will be executed and receive the stored metadata of record as parameters records. Inside the lookup enricher script, you can check with external sources and then you need to update the actual record in the database. Finally mark the enrichened record in enricher_<enricher_id> as deleted, the system will remove all cached data records marked as deleted once done.
Package requirements
- Upload lookup enricher package as
.zip.
enricher.py example (LOOKUP)
def enricher(enricher , records , utils=None):
chunk_size = 500
parameters = json.loads(enricher['parameters'])
enricher_index = f"enricher_{enricher['id']}"
try:
for data_start in range(0 , len(records) , chunk_size):
# get list of records to enrich from the records list
data = records[data_start:data_start+chunk_size]
if len(data) == 0:
break
# collect all keys to get it from ES if exists
keys = []
for d in data:
if d['_source']['key'] not in keys:
keys.append(d['_source']['key'])
# get the keys from cache first
es_keys = utils.es.cache_get(index=enricher_index , keys=keys)
results_to_store = {} # contains results as {key1: meta1, key2: meta2, ...}
records_to_delete = [] # contains list of record ids to be deleted from the case (type:`data`)
# enrich the data records
for d in data:
# delete the enriched record
records_to_delete.append(d['_id'])
try:
results = utils.es.cache_validate(cache_set=es_keys , key=d['_source']['key'])
# if the record not found in the cache, pull the info from external source
if results is None:
results = fetch_from_external(record=d, utils= utils)
# add to results_to_store so that it will store results in cache.
results_to_store[d['_source']['key']] = results
if results is not None:
# build the enrichment information document
enrichment = {
'description' : f"Indicator {d['_source']['key']} enriched by {enricher['name']}",
'type' : 'file', # list of https://www.elastic.co/guide/en/ecs/current/ecs-threat.html#field-threat-enrichments-indicator-type
'name' : d['_source']['key'],
'provider' : enricher['name'],
'matched': {
'field' : d['_source']['src_field'].lstrip("_source."),
'occurred' : str(datetime.now()),
'atomic' : d['_source']['key']
},
'last_seen' : results['last_seen'],
'Details' : {
f"{enricher['name']}" : results
},
}
# build the tags to be added to the tags field
new_tags = ['detected']
# update the enricher field
results = utils.es.update(index=d['_source']['rec_index'] , data=[enrichment] , id=d['_source']['rec_id'] , field_list='threat.enrichment.indicator', get_source=False)
# update the tags field
results = utils.es.update(index=d['_source']['rec_index'] , data=new_tags , id=d['_source']['rec_id'] , field_list='tags', get_source=False)
except Exception as e:
utils.logger.warning(f"Failed to enrich the record [{d['_source']['rec_id']}] in index [{d['_source']['rec_index']}]: {str(e)}")
# delete records after enriching
if len(records_to_delete):
results = utils.es.update(index=enricher_index , data={"delete": True} , id=records_to_delete, get_source=False)
# store the collected results to cache
if len(results_to_store.keys()):
success_records , failed_records = utils.es.cache_set(index=enricher_index, key_meta=results_to_store)
utils.logger.debug(f"New results from {enricher['name']} stored, Success:{success_records}, Failed: {failed_records}")
except Exception as e:
utils.logger.warning(f"Failed to enrich by [{enricher['name']}] enricher : {str(e)}")
return TrueLookup Cache Index Reference (enricher_<enricher_id>)
Lookup flow stores staged metadata in enricher_<enricher_id>. This index can also be used as temporary cache for enrichment results.
| Field | Description | Example |
|---|---|---|
date | Date/time when record was stored in cache index. | 2024-01-01 00:00:00 |
dest_field | Destination field from enricher parameters where enrichment should be written. | _source.threat.enrichment.indicator |
src_field | Actual source field path used to collect value from source record. | _source.file.hash.sha1 |
rec_index | Source record index ID in database. | case_5 |
rec_id | Source record ID in database. | c2b7e2b0-57de-4b34-a0d0-6cda1e1e8e5b |
key | Value extracted from src_field and used for lookup/cache matching. | 8.8.8.8 |
type | Record type for lookup staged data. | data |
Important operational guidance:
- Mark cache data records as deleted after enrichment to avoid repeated processing.
- Keep output fields conflict-free across enrichers. Under
Details, store data by enricher/provider name (for exampleData.AlienVault.<fields>pattern). - Cache is optional but strongly recommended for performance when external sources are slow or rate-limited.